
I’m not planning on going into the decision-making process of choosing Sphinx and Thinking Sphinx for our search implementation, but I will say that it was carefully considered and researched. There are advantages and disadvantages to every option, and everyone has different needs. This combination just happens to be the one that works best for what we wanted to do.
How it All Works
Before I get too carried away talking about the technical bits, it’s worth looking at the big picture of how everything fits together. We chose to use Sphinx and Thinking Sphinx for Sifter. I’m going to gloss over some of the finer points in favor of keeping this simple.
Sphinx
Sphinx, by Andrew Aksyonoff, is a full-text search engine. It includes both indexer and searchd which, unsurprisingly, handle the index creation and search requests respectively.
Thinking Sphinx
Thinking Sphinx is a Ruby library by Pat Allan that plays the go-between for ActiveRecord and Sphinx including rake tasks for configuring, indexing, and starting/stopping the search daemon.
Pieces of the Puzzle
There are several elements that come together so that everything works. I’ll be focusing exclusively on our specific so setup. We’re relying on delta indexing, which is optional, but since it’s more complex than not using delta indexing, this is a safe superset of what can be done.
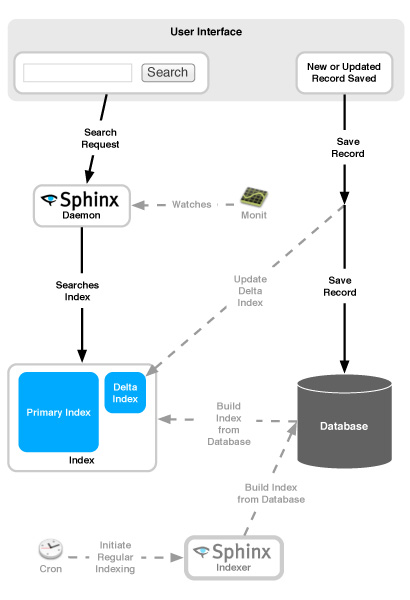
- Configuration – Much of the configuration is handled within your models, and the model-independent options are configured in a sphinx yaml file in config. (/config/sphinx.yml). Running the rake thinking_sphinx:configure rake task will generate the actual Sphinx configuration file for you based on the settings in your models and your Sphinx yaml file.
- Search Daemon – This is the daemon that actually handles the search requests.
- Indexer – The indexer creates the index. In order to keep the index up to date, we have to regularly run the indexer, which in the case of Thinking Sphinx, runs a full reindex each time.
- Index – The index is just like the index to a book. It’s a series of files created by the Sphinx indexer so that it can efficiently perform searches.
- Monit – Occasionally, the search daemon will die, so Monit keeps an eye on it to ensure that it’s resuscitated in these rare situations.
- Delta Indexing – Because the index is maintained separately from the database, by default, it won’t reflect changes to the database until the next indexing occurs. Depending on your configuration, that could be hours or days. Delta indexing enables your app to essentially update the index every time a searchable record is saved by maintaining a delta index in addition to the primary index. Then, when a search request is sent, both indexes will be searched. The disadvantage to this is saving records will inevitably slow down as the size of the delta index increases. Regularly re-indexing helps ensure that the delta stays small and keeps performance high. There are other options, but I’ll be focusing on our implementation.
Installation & Setup
With all of the moving pieces, Sphinx isn’t trivial to setup, but it’s really not too bad either. I’ve tried to pull together the resources that I found most helpful at each stage of the game so that it’s easier to get through the process. All of these steps are well-documented elsewhere, so instead of reinventing the wheel, I just wanted to pull together all of the relevant resources based on the process I went through setting things up for Sifter.
Installation
Installation was straightforward, and both Sphinx and Thinking Sphinx have fantastic installation instructions.
Configuring Sphinx & Thinking Sphinx
For configuration, there are extensive details on both Sphinx Configuration and Thinking Sphinx Configuration which explains how to configure Sphinx through the sphinx.yml file.
Configuring Your Searchable Models
The Thinking Sphinx usage guide covers most of the basics on how to setup your models. The most significant aspect of this configuration for us was enabling delta indexing which takes advantage of Rails callbacks to automatically update the delta index after a relevant record is saved or updated. While we went with standard delta indexing, several additional options for delta indexes are available.
Monitoring the Search Daemon
From time-to-time, the search daemon will die, so keeping an eye on it is important. Adding a section to our Monit configuration file for the search daemon was fairly straightforward. I’ve include the relevant section of our Monit config file below. Make sure to replace anything in all caps with the values for your system.
check process searchd with pidfile /YOUR_PATH_TO/searchd.pid
start program = "/YOUR_PATH_TO/searchd --config /YOUR_CURRENT_PATH_TO_RAILS_APP/config/ENVIRONMENT.sphinx.conf" as uid USER and gid GROUP
stop program = "/YOUR_PATH_TO/searchd --stop --config /YOUR_CURRENT_PATH_TO_RAILS_APP/config/ENVIRONMENT.sphinx.conf" as uid USER and gid GROUP
if failed host localhost port 3312 then restart
if 3 restarts within 5 cycles then timeout
Initiating Regular Indexing
Even if you’re using delta indexing, you’ll still want to regularly reindex because the larger the delta gets, the slower your saves and updates will become. Cron is the natural choice here. You’ll just need to setup a cron task to run the rake thinking_sphinx:index task on a regular basis and you’ll be all set. The indexer is incredibly fast, on a small site, you could probably get away with running it every 5 minutes or so without any problems. However, with delta indexing turned on, frequency is less important, so we’re running it once per hour.
Managing Deploys
While it wouldn’t be the end of the world to reindex with every deploy, I wanted to avoid having to rebuild it every time. Instead, we’re following in Wade’s footsteps and keeping the index in our shared path and then creating the symlink to it on each deploy.
Wade mentions in hist post that Thinking Sphinx generates the actual Sphinx config file from your models and sphinx.yml using rake thinking_sphinx:configure. The resulting file will be used when the Sphinx search deamon is started. So, with each deploy you’ll want to manually rebuild the Sphinx configuration file in order to ensure that any relevant changes in your models or sphinx.yml get updated within the file that Sphinx uses. So, just after the symlink and before we restart the Sphinx search daemon, we make sure to run rake thinking_sphinx:configure to make sure it will start itself up with the new settings.
Additional Resources
I would have never made it this far without the following resources, and of course many thanks go to Andrew Aksyonoff and Pat Allan for providing such wonderful tools to the community.