
Having thought about this for years, I decided some time ago that if I was going to build an issue tracker that I’d have to start by creating a simple issue life-cycle and workflow. That was the heart of the problem, in my opinion. If the workflow wasn’t simple, the software wouldn’t be either. You might be familiar Conway’s Law which more or less states…
Any piece of software reflects the organizational structure that produced it.
It doesn’t take much to see that a complex issue life-cycle would lead to complex software. For me, it was more important to define one clear and simple process instead of a flexible and customizable one. So I set out to create “the perfect process”, and this is the abbreviated version of how it came about.
The Vision
Before we get into the diagrams, it’s important to understand that I’ve come to hold two aspects of the process as sacred. The first is status which is the primary focus of this article. The second is responsibility. Anytime I run into a problem on this project, these factors play the most significant role in how I determine on a solution.
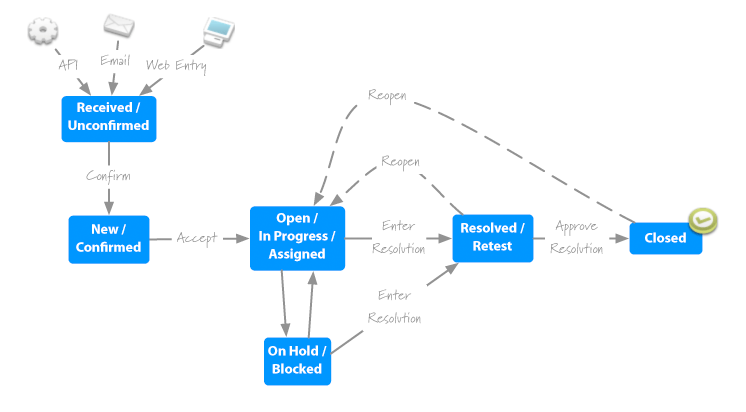
I started with a reasonable, but thorough, life-cycle. 1 It bothered me that there were two steps to even get the issue to a point where someone was working on it. 2A & 2B These steps enable large teams and open-source projects to verify that issues are legitimate before anyone begins working on them, but they’re overkill for smaller teams. They had to go.
By removing these steps, it freed me to simplify the name of the initial status to “Open”. So, instead of “accepting” or “confirming” an issue, we just assume that all issues are good, and if they’re not, we can close them with an explanation of why they’re invalid. It accomplishes the same thing, eliminates complexity, and provides a more natural path to a resolution. More importantly, it helps make status and responsibility more distinct. Instead of “accepted”, an issue is implicitly accepted when it’s assigned. At that point, it’s up to that person to do something with it.
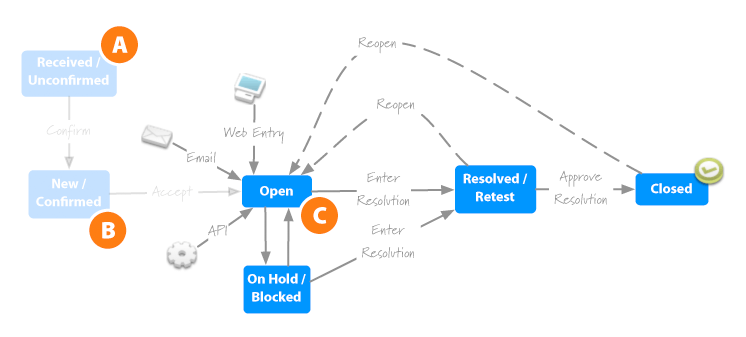
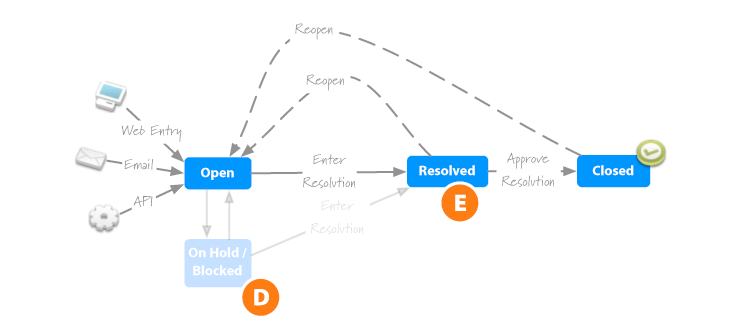
While we’re on the subject of accountability, I decided that putting an issue “on hold” is like sweeping it under the rug. 3D It’s a convenient way to avoid responsibility. The only benefit of putting an issue “on hold” is that it provides the illusion of progress. As far as I’m concerned, those are still open, and the distinction only serves to dilute accountability. If something or someone is preventing progress, the issues can and should be reassigned to someone who can do something about it.
In addition to removing the ability to put things on hold, I chose “Resolved” for the label on the next step instead of “Retest”. 3E While I anticipate that it will primarily be used for tracking bugs, I see a lot of potential in using it to track generic issues as well, and “Retest” just doesn’t really apply to generic issues. It’s a little thing, but they all start to add up.
Now that we’ve cut out the excess, we’ve got a life-cycle that I’m comfortable using. 4 More importantly, the life-cycle is simple enough that even a non-technical client or coworker can understand how it works without being intimidated. And of course, now the language is flexible enough so the system can be use for both software defects and generic issues.
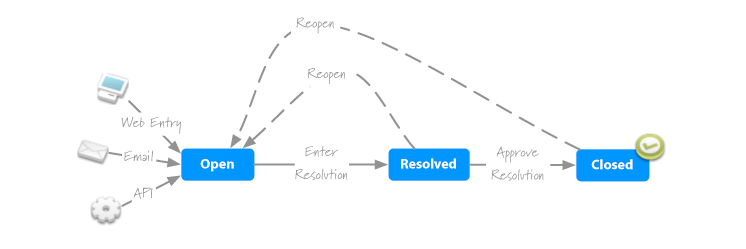
To some, I’m sure this will appear to be insufficient and an over-simplification, but it was a key step in enabling me to create a solution that was focused on getting work done. Now the process gets out of the way and lets people focus on progress.
Summary
I’ll be honest. Writing about vaporware is a little scary. However, I’m a big fan of sharing best practices and lessons learned, so I’ll be doing my best to get past that fear. Ideally, when it’s all said and done, we’ll have a whole series of informational articles like this one in addition to some great software.
I’ve looked at a lot of bug tracking solutions, and they’re all pretty complex. They work for some situations, but for the other situations, we need something simpler. Hopefully this can be it.